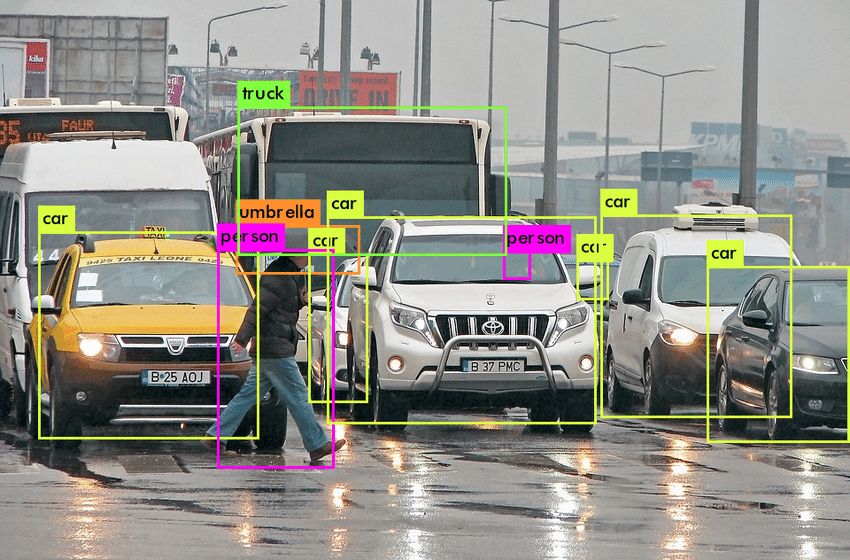
This is a Class Agnostic Detection problem, where we need to localize the object irrespective of the class.. My approach is similar to single shot detector algorithm such as YOLO and SSD, except the feature extraction pipeline. To extract class agnostic feature, I used conditional feature to put more attention on the object. This trick helped me to secure a rank of 36/6733 in the competition at dare2complete platform, sponsored by Flipkart.
Python, Tensorflow, Augmentation, YOLO, SSD
The objective of this project is to design a model for Amazon Product Review Classification. This was Multilabel Classification Problem. My approach includes feature preprocessing, engineering and finally built an ensemble of model such as SVM, Logistic Regression, Decision Tree, Attention Model and BERT to accurately categorize the Amazon Product Review. This ensemble helped me to land in top shortlist for Amazon-Business-Intelligence profile.
EDA, Scikit-Learn, Xgboost, Embedding, BERT, Ensemble
This is my one of favorite project. The challege was to design a model for Risk Prediction for a financial coorporation (HDFC). We were given approximately 2500 unknown predictors. I experimented with several feature selection and feature engineering methods, during the contest. And finally, designed an efficient algorithm for interaction based feature, along with feature selection using decision tree. This repo also ha report on broad analysis of these predictors.
Python, EDA, Scikit-Learn, statsmodels, GBM, H2o, Stack-Net
This is a link prediction challenge for Hike Messenger. We were given a very big dataset, which doesn't fit in memory. During this project, I worked on feature engineering for graph dataset, graph neural network, memory optimization etc. My final approach is to collect all the feature and run LightGBM and CatBoost. My model secured a rank of 32/5389 in ML-Hikeathon contest. After the competition, I worked on subsemble model for large dataset.
GraphX, GBM, Keras, Word-Embedding, Subsemble
This is my research project on deep learning. The objective is to undertand the image feature used by deep cpnvolution feature and improve the model accuracy on Cifar-10 dataset. I designed an architecture, where base model is ResNet, but head model extract feature by using global as well as local feature of the image. This technique improves accuracy by 1.37%. As the designed method igores the irrelevant information in the input image, therefore final attention map is much better than simple ResNet
Python, Tensorflow, Attention Mechanism, Visulization
This was my college project, where objective was to build a student-attendence system. Its input is image of a person and output is a verification task, if person is registered in the course. The collected dataset was very small. So to train a deep neural network model, I adopted network in network architectureI for my Maching Network. I trained it using hard-mining technique, and got 93% accuraacy.
Tensorflow, Keras, ImageAug
In this project, I first implemented an U-Net architecture and trained on blood cell Dataset (on Kaggle). I extend it to multi-stage network, to improve score. I also experimented with differnt configuration of Fully Convolutional Network for traffic-street dataset. Finally I experimented with Generative Adverserial Network for Data Augmentation, to learn better feature (But sadly did not get success).
Python, Tensorflow, Keras, FCN, U-Net, GAN
The objective of this problem is to recommend question to users, on a coding platform. So we have to answer question like, which question user should solve next? How about when user get stuck? etc. My approach is a hybrid approach using matrix factorization, content based, collaborative based and deep and shallow model. I used TF-IDF and word embedding, both for feature extraction in my model.
Python, Tensorflow, Word-Embedding, Graph, Gradient-Boosting, Ensemble
This repo contains various data science strategy and machine learning models to deal with structure as well as unstructured data. It contains module on feature-preprocessing, feature-engineering, machine-learning-models, etc. Some of these features are collected from the existed libraries such as scikit-learn, keras, gensim, h2o, bayesopt, xgboost, lightgbm, catboost, GraphX etc and others are implemented by me, by following the Research Paper and advices on kaggle.
Python, Tensorflow, Word-Embedding, Graph, Gradient-Boosting, Ensemble