Lottery Ticket Hypothesis
Generally, in deep learning, we build a deep model and then prune some weight of model (which don’t effect the accuracy). Using this process, we can get a smaller size network (75% - 90% in size) at same accuracy. But what happens, if we train the subnetwork again? Will the accuracy improves? Can we reduce the size of network further? AI researchers have found that their accuracy decreases if we retrain the pruned network. So they cann’t be pruned further. But researchers from MIT challenge this assumption and proposed a smart method to prune the model upto 0.3% with samewhat similar accuracy.
They experiment with the initialization of the network and found that if we reinitialize the pruned network with the new random value, it performance decreases. But if they are re-initialized with the same weight value that are used at the start of training, we can get same or even more (sometime) on the trained model. They call this subnetwork as a winning ticket in big deep network.
Algorithms:
Randomly initializea neural networkf(x; θ)(call itθ_0)Trainthe network forkiteration, so the parameter becomesθ_kPrunep%of the parameterθ_k(create a maskmfor that)Resetthe remaining parameters to their value inθ_0, creating the winning ticketf(x; m*θ_0)Repeatstep2-5, till theaccuracychange are inthresholdlevel.
Their experiment result are unbelieve. Iterative pruning make training much faster with better generalization. They proves that we can achieve same test accuracy with only 10% - 20% of the original model. And this technique can be applied on any neural network structure.
In the following image, we can see that the model performance is 0.3% more than original model with only 1.2% of the original model.
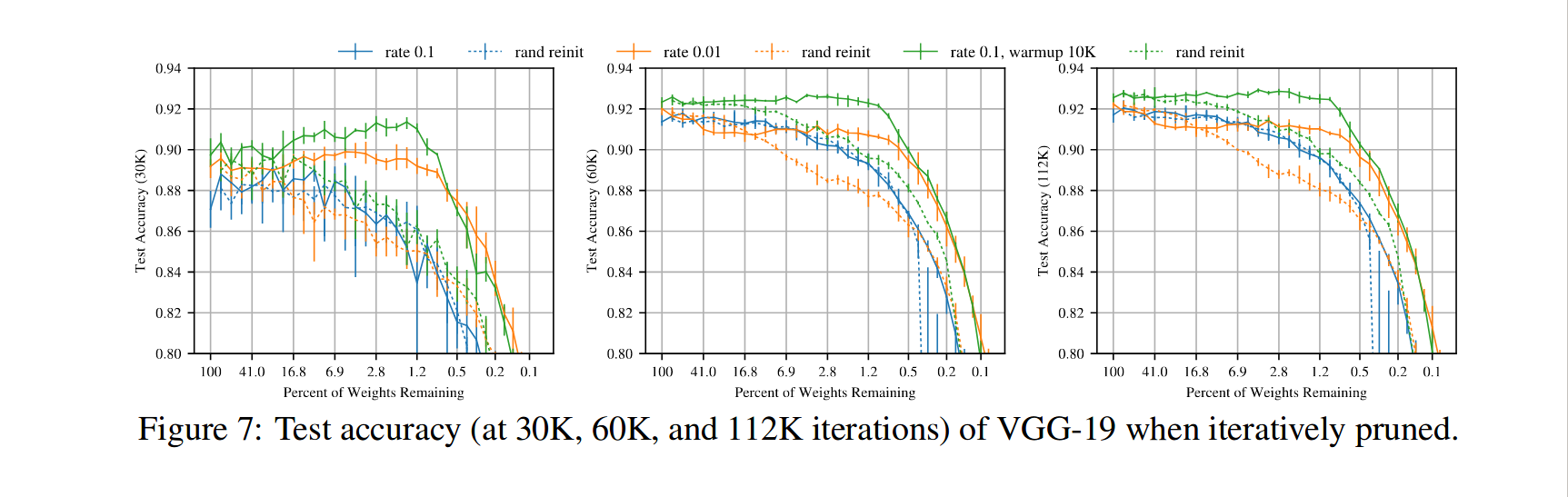
Let’s talk about if this concept is related to our learning mechanism. I believe that our brain has a similar pruning mechanism. When we read a topic, it make some connection with weak and strong synaptic weights. But when we go through that topic again and again, some of the weak synaptic weight’s connection breaks and other becomes more strong. It also create some new connections based on a relation between the current topic and our prior experience. Except this facts, this proposed technique behave the same. Following this, we can raise question like, how to choose hyper-parameter k, to train a model after pruning step? What would be the best pruning percentage value p? Author has done a detail analysis of these questions, please check out paper.